
ground truth
model prediction
1. Reproducing paper results
The paper does two things: releases TFUScapes, a 3D dataset of simulated tFUS pressure fields through MRI-derived skulls, and proposes DeepTFUS, a 3D U-Net that predicts those fields from a CT volume and transducer position. However, at the time of writing, weights and training code have not been released, and §3.2 leaves several implementation specifics unspecified[1] so this reproduction has to fill in some gaps.
Three metrics we care about
The paper reports three numbers on a 597-sample held-out test set. (Lower = better for all three).
relative_l2
Is the field shape right?
Total error between the predicted and ground-truth 3D pressure fields, normalized by ground-truth magnitude.
41.4% ± 8.6 paper mean ± std
focal_position_error_mm
Where does the focus land?
Distance in mm between where the model places the peak pressure and where the ground-truth simulator places it.
2.89 ± 2.14 mm paper mean ± std
max_pressure_error
How strong is the focus?
Relative error in peak pressure intensity.
19.9% ± 15.8 paper mean ± std
My base reproduction vs the paper
50 epochs from scratch using the paper’s composite loss exactly, with two small architecture deviations to fit the “batch size of 4 on a single A100” memory budget the paper specifies[2]. Training ran for about 11 hours on a single H100 80GB (1686 train / 200 val / 597 test, batch size 4, pure-bf16, peak ~69 GiB of GPU memory).
| variant | relative_l2 | focal_position_error_mm | max_pressure_error |
|---|---|---|---|
| DeepTFUS (paper) | 41.4% ± 8.6 | 2.89 ± 2.14 mm | 19.9% ± 15.8 |
| DeepTFUS-tiny (paper) | 41.0% | 2.95 mm | 19.6% |
| base(mine) | 38.4% ± 7.8 | 6.49 ± 4.58 mm | 22.5% ± 11.6 |
relative_l2 is slightly improved upon (38.4% vs paper’s 41.4%), max_pressure_error is within paper’s spread (22.5% vs 19.9% ± 15.8), but focal_position_error_mm is the one that didn’t reproduce: my model’s focus lands 6.49 mm off on average versus the paper’s 2.89 mm. (Alongside these three, I also evaluated the three TUSNet metrics that apply to DeepTFUS: focal pressure error, focal IoU at FWHM, and inference time. Full breakdown in the appendix .)
Visually:
Qualitative results from test set
ground truth
model prediction
5th percentile placement (1.2 mm off)


25th percentile placement (3.4 mm off)


75th percentile placement (8.7 mm off)


95th percentile placement (14.7 mm off)


I suspect the focal-position gap is a capacity issue, i.e., my 3.4M model isn't large enough. The base model plateaued early (weighted-MSE flatlined around epoch 30 and stayed there for the final 20 epochs) without overfitting (the train↔val gap stayed flat). The next training run (if there is one) should probably double base_width from 16 to 32.
Validation metrics over base training

2. Closing the focal-position gap
Because this was a quick learning sprint, it seemed more reasonable to continue training the base checkpoint for another 5 to 10 epochs (especially since there had not been overfitting yet) with a modified loss and see how each variant moved the metrics. Each fine-tune below is a continuation from the base with a change to the loss function.
Can we add an explicit position loss without degrading the other metrics?
The paper’s loss
Training drives a composite loss with two terms:
is a spatially-weighted MSE that puts most of its mass on the voxels near the focal spot, since that’s the only region that physically matters. In practice the weight runs from ~0.3 in background voxels to ~10 at the focal peak; without it, the model would learn to drive whole-volume MSE to zero by predicting near-zero pressure everywhere (the focal spot is <1% of the voxels).
is a gradient-consistency term that asks the predicted field’s spatial derivatives to match ground truth’s along each axis, encouraging clean focal-zone boundaries instead of blurry blobs.
Every fine-tune below is a one or two-line change to this recipe.
The five variants
Each starts from the base checkpoint and changes effectively a single line of the loss.
The dominant idea is a soft-argmax L1 focal-position term that supervises the location of the predicted hot spot directly:
soft-argmax is a temperature-controlled differentiable expectation of voxel coordinates over a softmax of the predicted pressure; smaller gives sharper peaks, closer to true argmax[4]. The fine-tunes vary , , and whether the paper’s gradient term stays on as an anchor.
Conservative test: does any soft-argmax move focal_mm without breaking rel_l2?
Finding. Modest position improvement (focal_mm 6.49 → 5.60 mm mean, ~14% better than base), and the only variant where max_p actually improves over the base run (22.5% → 20.4%). Not bad!
5× stronger focal pressure, sharper , gradient anchor dropped (testing the hypothesis that was diluting the focal signal).
Finding. Stronger position win (focal_mm 5.06 mm mean), but max_p degrades to 24% and stray off-target hot-spots multiply (probably due to dropping , which evidently had been pulling the predicted field’s spatial derivatives toward ground truth’s).
B exactly except add the anchor back.
Finding. Statistically tied with B on the three paper-canonical metrics (focal_mm 5.11 vs 5.06 mm; rel_l2 and max_p essentially identical) but performs slightly better on our additional metrics.
The “position over everything” point on the trade-off curve. Sharpest , biggest , and 3× learning rate to push past C’s plateau.
Finding. Best focal_mm of any variant (4.19 ± 2.93 mm mean, ~35% better than base), but predictably the rest of the metrics degrade: rel_l2 climbs to 42.2% (the first variant to exceed the paper’s budget) and max_p climbs to 28.3%. (Somewhat of a trivial result?)
Variants A–D all landed the peak in roughly the right place but predicted a focal blob too wide around it: soft-argmax only constrains where the centroid sits, so a tight concentrated peak and a fat diffuse blob with the same centroid satisfy it equally well, and the optimizer prefers the fat one (smoother predictions are easier to fit elsewhere).
directly goes after the shape by measuring how well two 3D blobs overlap: the focal region thresholded at half the peak pressure in the predicted field, and the corresponding region in the ground-truth field. Dice measures how well those two blobs overlap; a soft, differentiable version is used here so it can drive gradients. Effectively, the new loss term gives the model a signal that says exactly which voxels should and shouldn’t be in the focal region, and not just where its center should sit.
Finding. Brings max_p to 12.9% (well below the paper’s 19.9%), and is the only variant that tightens the predicted focal region rather than letting it spread. Trades back ~0.2 mm of focal_mm vs C, probably because the Dice and soft-argmax terms compete for the same gradient mass.
Validation curves over fine-tuning
Before the final test-set numbers, here’s how each variant evolved on the 200-sample validation set during the fine-tune epochs:
Validation metrics over fine-tune training

A plateaus quickly on focal_mm because its position term is gentle; D drives focal_mm down hardest but its rel_l2 climbs out of the paper’s budget; E’s Dice term collapses max_p almost immediately and stays there.
Final results
| variant | relative_l2 | focal_position_error_mm | max_pressure_error |
|---|---|---|---|
| DeepTFUS (paper) | 41.4% ± 8.6 | 2.89 ± 2.14 mm | 19.9% ± 15.8 |
| base(mine) | 38.4% ± 7.8 | 6.49 ± 4.58 mm | 22.5% ± 11.6 |
| variant A | 38.9% | 5.60 mm | 20.4% |
| variant B | 38.8% ± 7.7 | 5.06 ± 3.57 mm | 24.0% ± 10.6 |
| variant C | 38.8% ± 7.7 | 5.11 ± 3.76 mm | 23.9% ± 10.6 |
| variant D | 42.2% ± 8.2 | 4.19 ± 2.93 mm | 28.3% ± 10.5 |
| variant E | 40.1% ± 8.1 | 5.32 ± 3.44 mm | 12.9% ± 9.5 |
Three takeaways across the variants:
- D closes the most focal-position gap at 4.19 mm mean (vs paper’s 2.89), but only by overshooting the
rel_l2budget. So D isn’t a clean reproduction; it’s the “position at any cost” corner. C is the strongest in-budget variant at 5.11 mm. - E (Dice) crushes
max_p, pulling it from baseline’s 22.5% all the way down to 12.9% (a wide margin below paper’s 19.9%). The Dice term explicitly penalizes the predicted half-max region from spreading wider than ground truth’s, which the soft-argmax variants couldn’t do. E gives back ~0.2 mm offocal_mmrelative to C in exchange. - The position metric still misses the paper. The best variant is 1.45× worse on the mean than what the paper reports. As discussed previously, probably a combination of my model not being large enough and some missed guesses at the architecture.
All six checkpoints (the base + five fine-tunes) are public on HuggingFace, browsable as the ![]() DeepTFUS reproduction collection . For the full per-variant numbers across the three paper-canonical metrics and the three TUSNet metrics that apply to DeepTFUS, see the appendix .
DeepTFUS reproduction collection . For the full per-variant numbers across the three paper-canonical metrics and the three TUSNet metrics that apply to DeepTFUS, see the appendix .
3. Analysis
These are quick experiments I had Claude run to help me understand the model better, which I felt were worth sharing.
What does the bottleneck encode?
The trained model squeezes its full 256³ input (a CT volume of the head plus a transducer point cloud) into a single 128-dimensional feature vector at its deepest layer (the “bottleneck”). For the most part, the decoder's downstream tasks (reconstructing the pressure field, placing the focal spot) depend on this bottleneck. So what's in there?
Linear probes give the cheapest answer. I trained tiny linear models to predict four candidate factors (subject identity, transducer azimuth, transducer aperture, predicted focal depth from skull) from the 128-d bottleneck.
What is recoverable from the bottleneck

So the bottleneck is a fairly complete joint summary of at least pose, geometry, focal depth, and anatomy.
Is the bottleneck smooth in transducer pose?
Two reasons this matters:
-
Generalization: a smooth pose-to-feature mapping is what lets the model interpolate to unseen poses instead of memorizing per-pose patterns.
-
Inverse problems: an eventual application (given a desired focal spot, where do I put the bowl?) is naturally solved by gradient descent on the placement, and that only converges if the loss is differentiable in placement all the way down to the bottleneck.
A direct check: rotate the bowl in small (~1.6°) steps around the head with everything else frozen (same patient, same bowl geometry, same CT), re-run the trained model at each step, and watch how a few of the deepest channels respond.
Sliding transducer sweep
Predicted pressure field with rotated transducer (red)
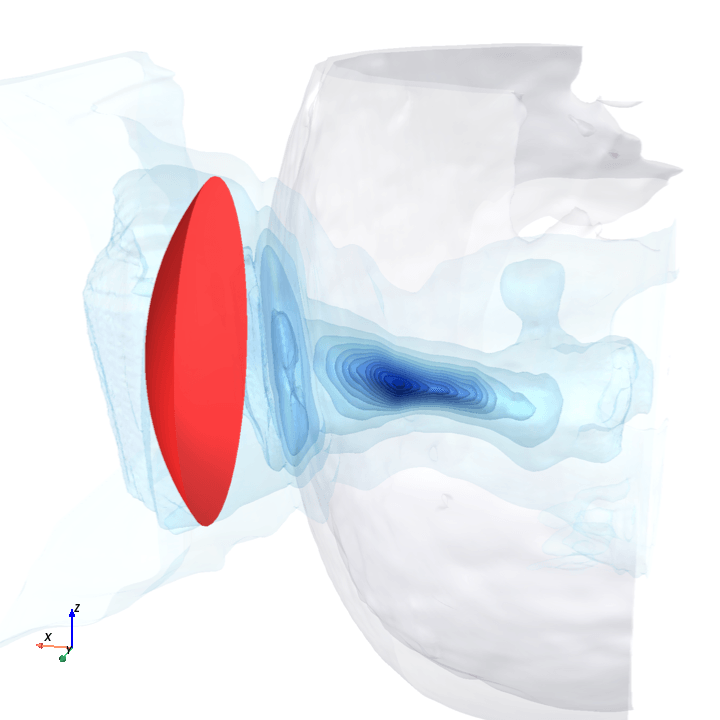
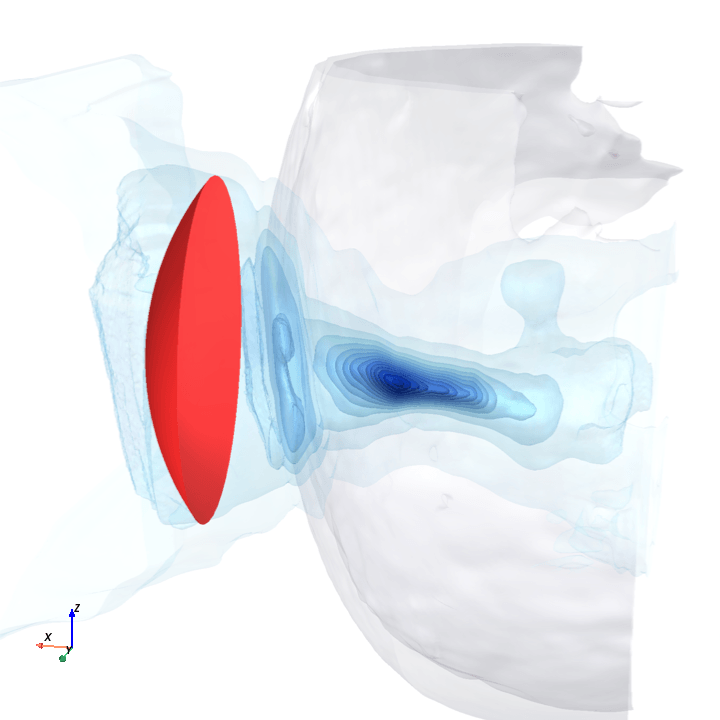
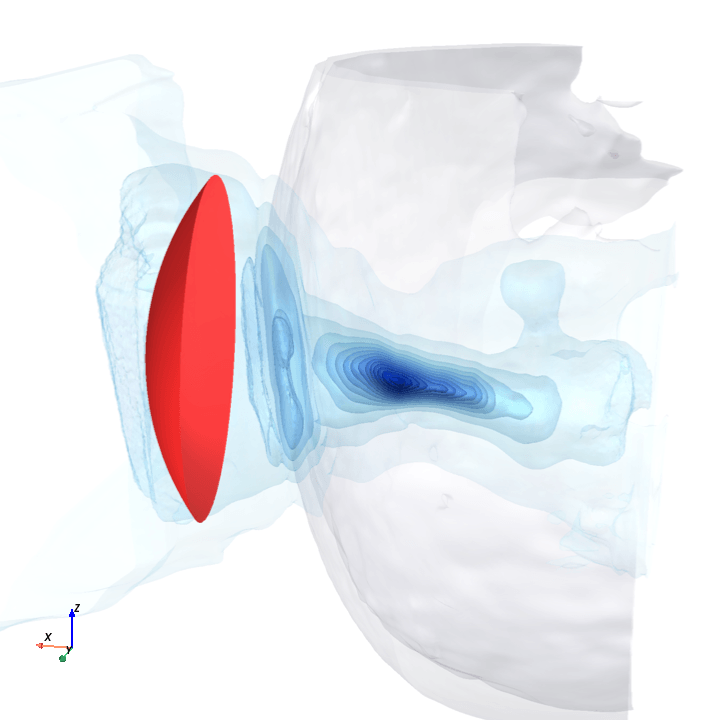
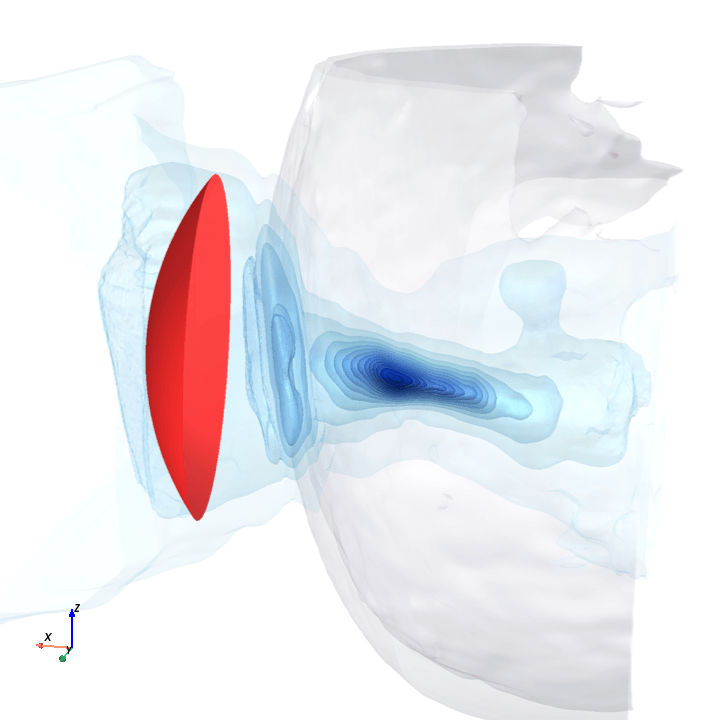
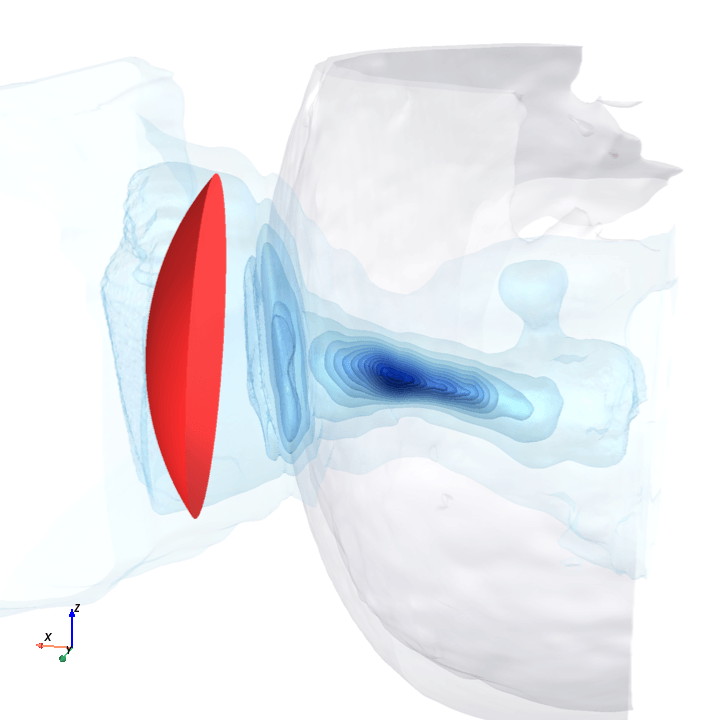
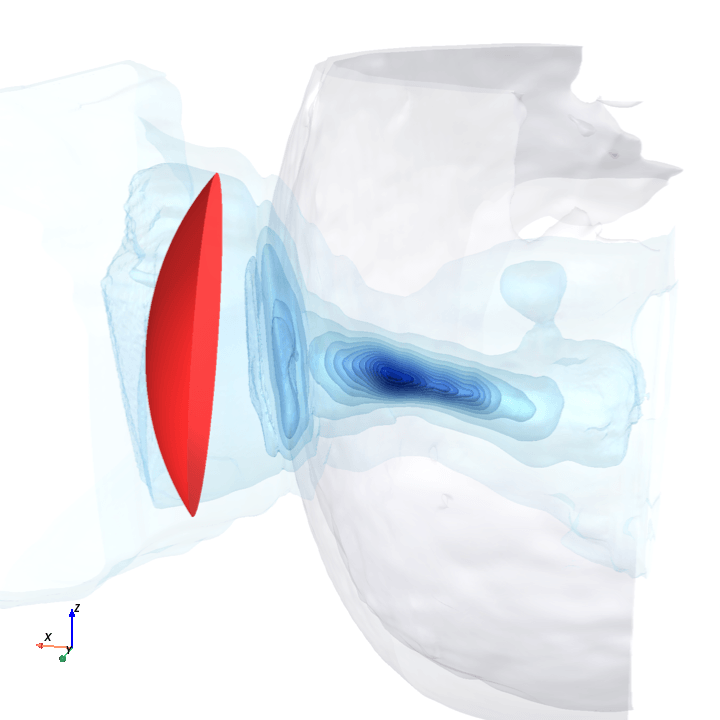
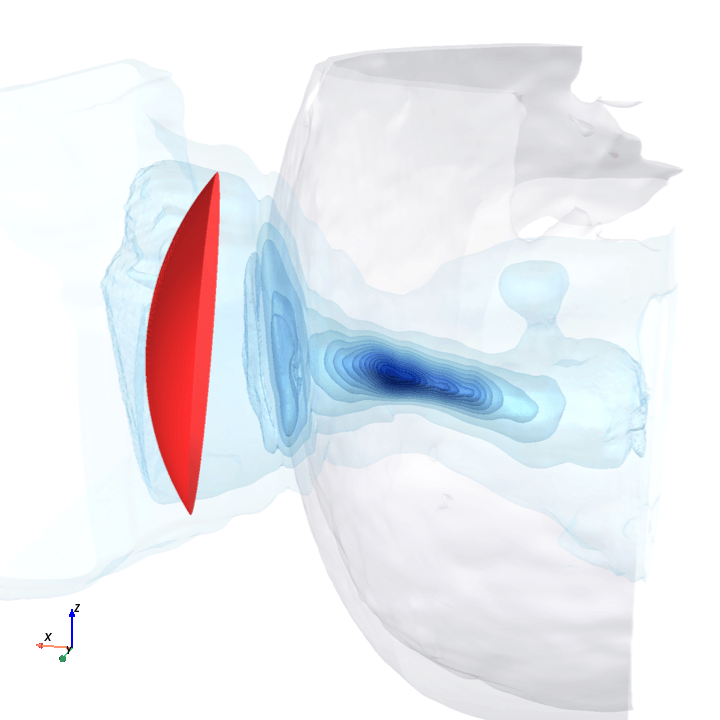
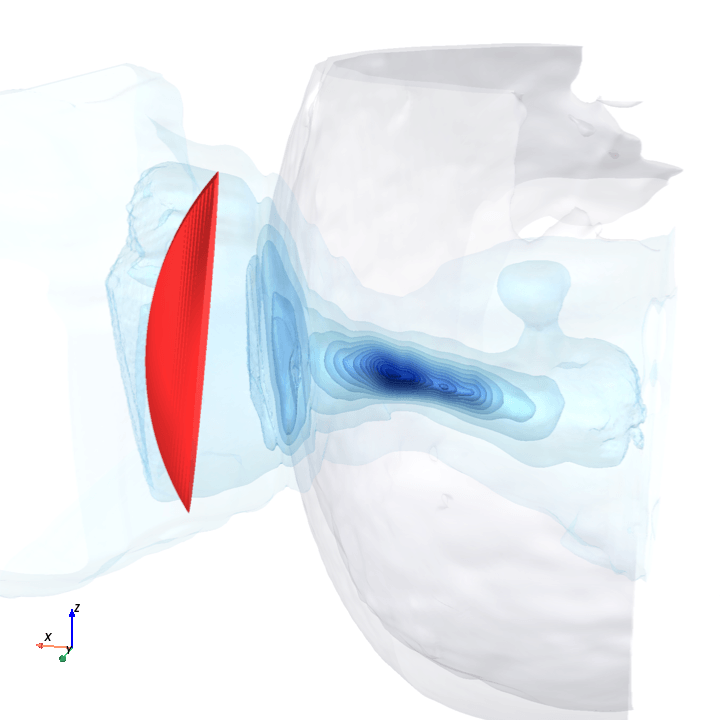
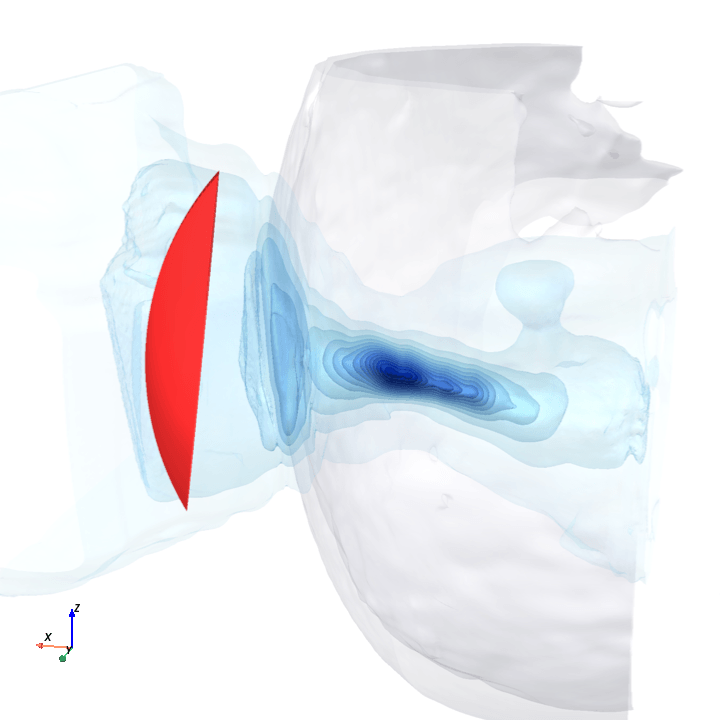
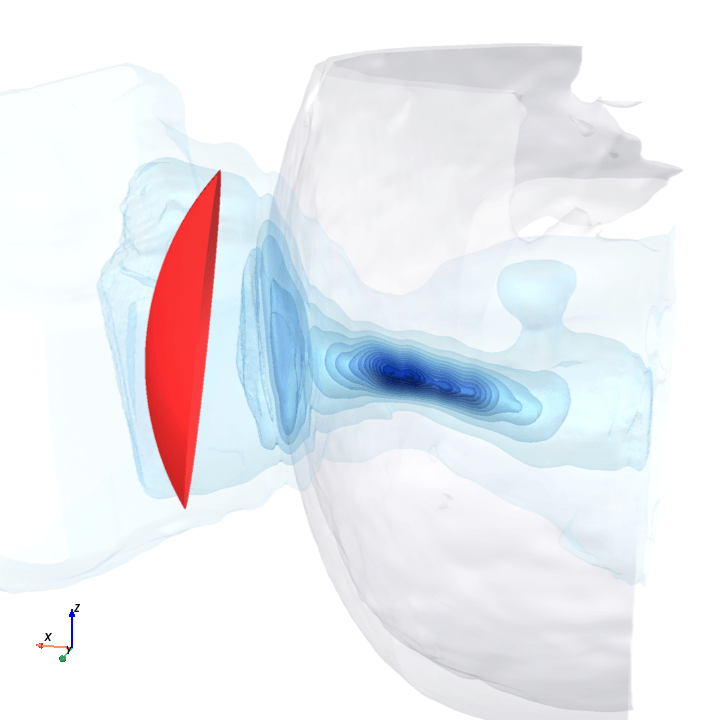
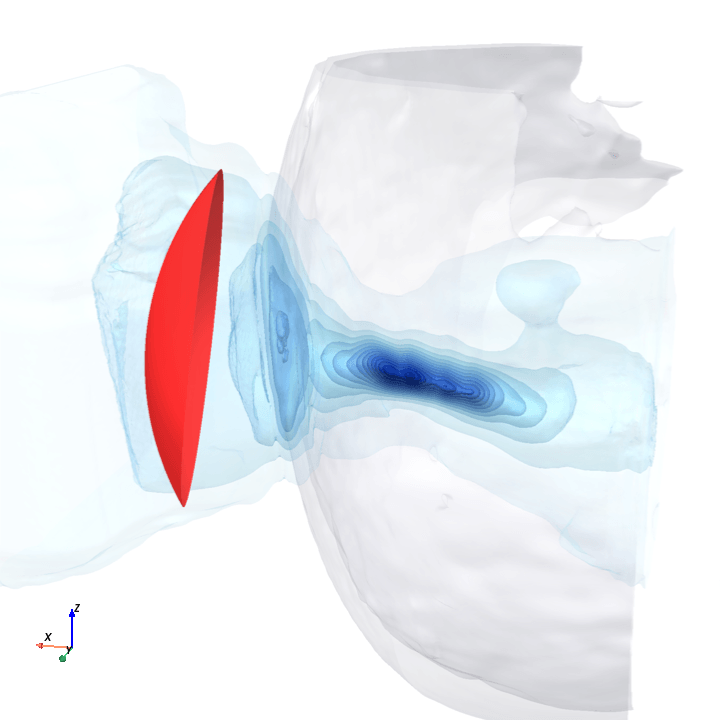
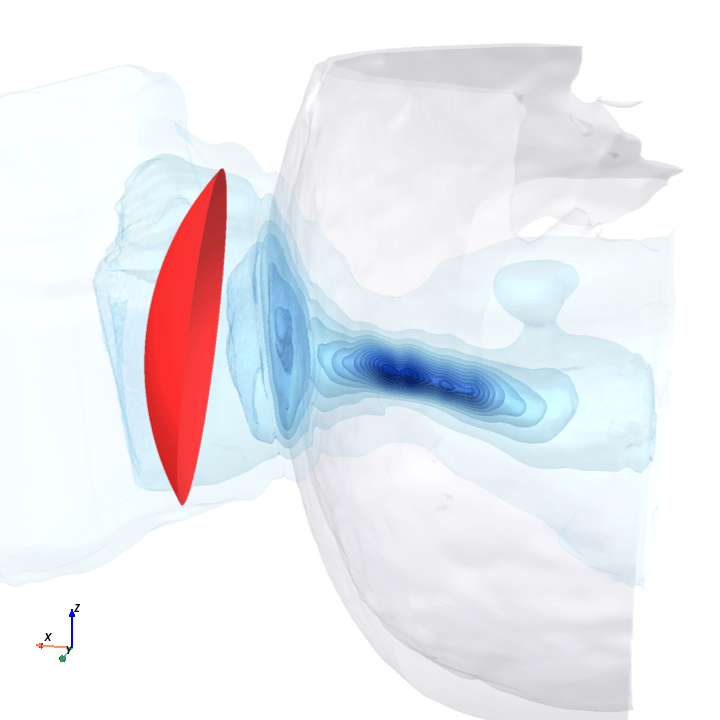
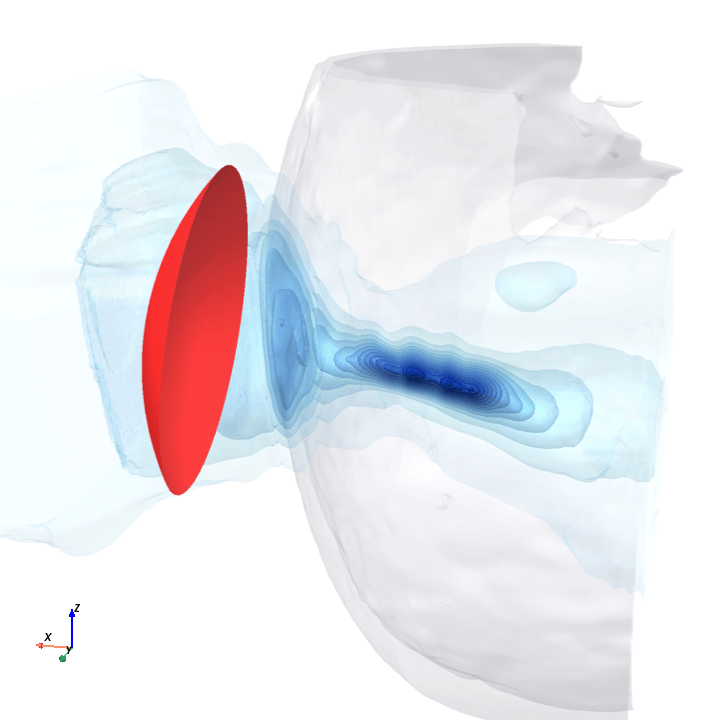
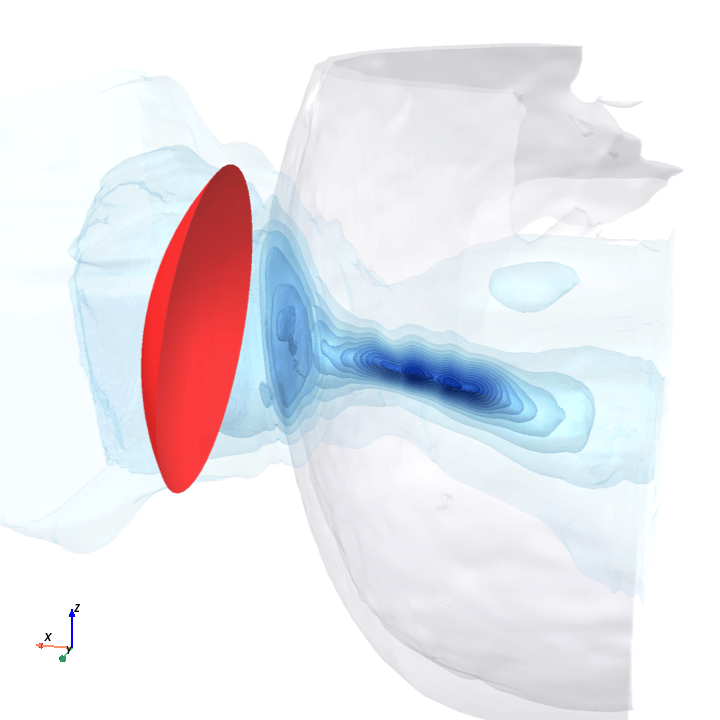
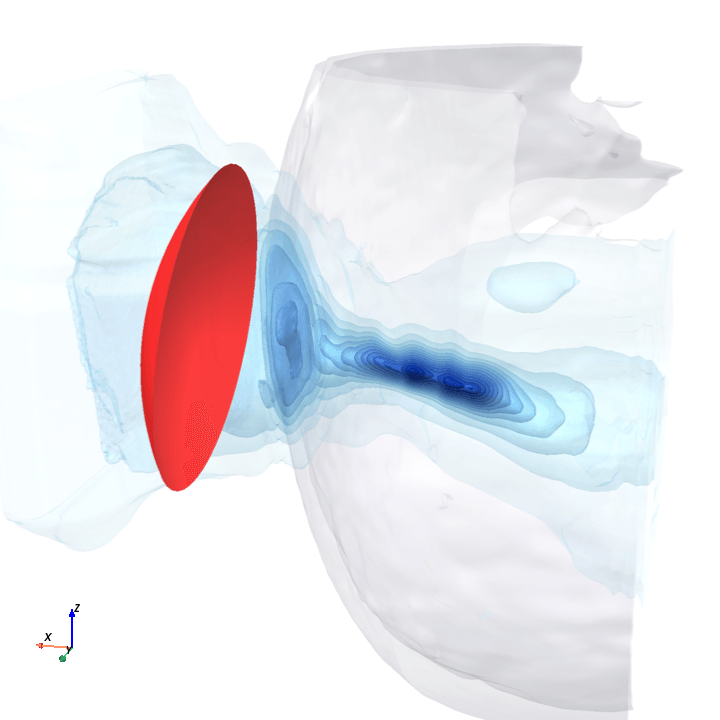

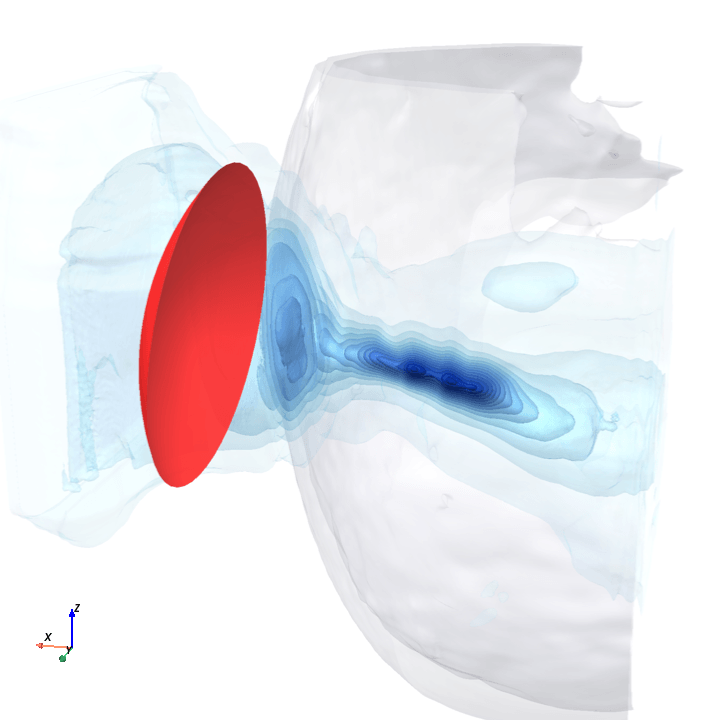
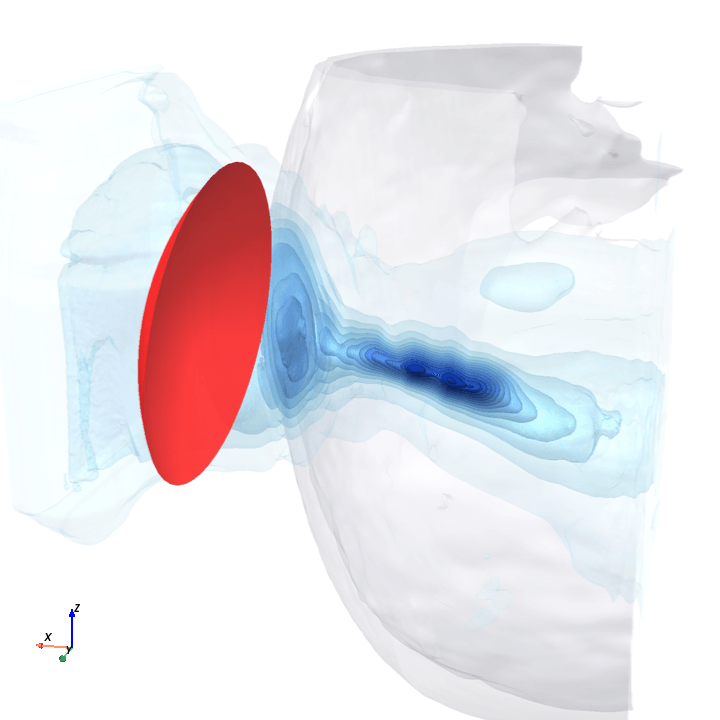
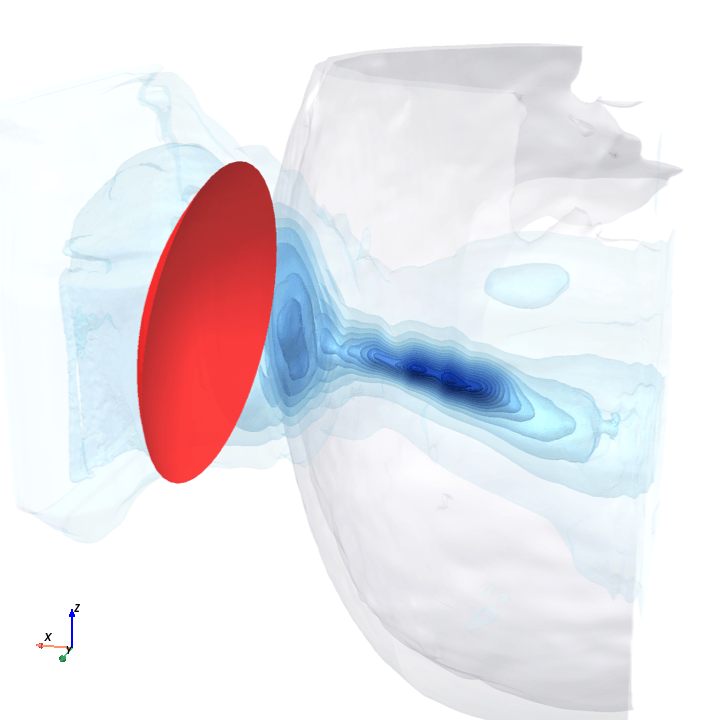
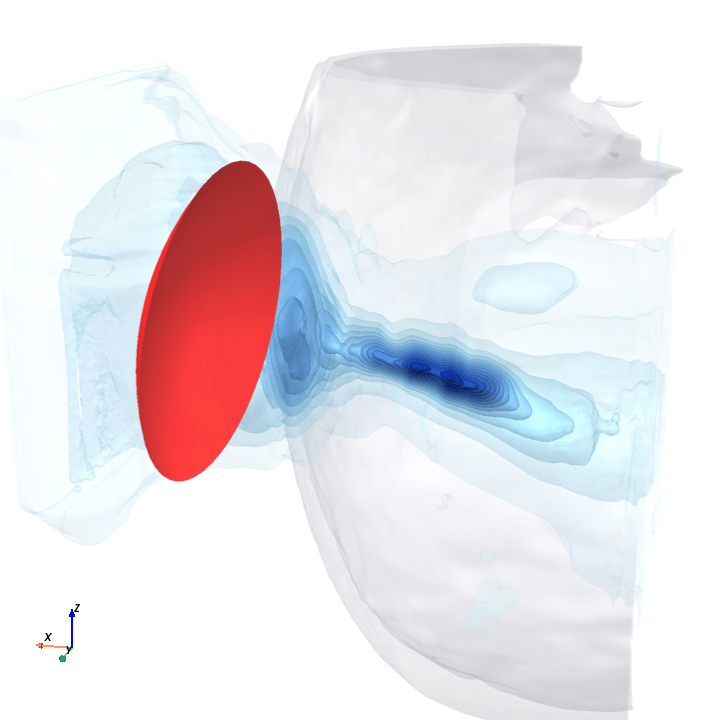
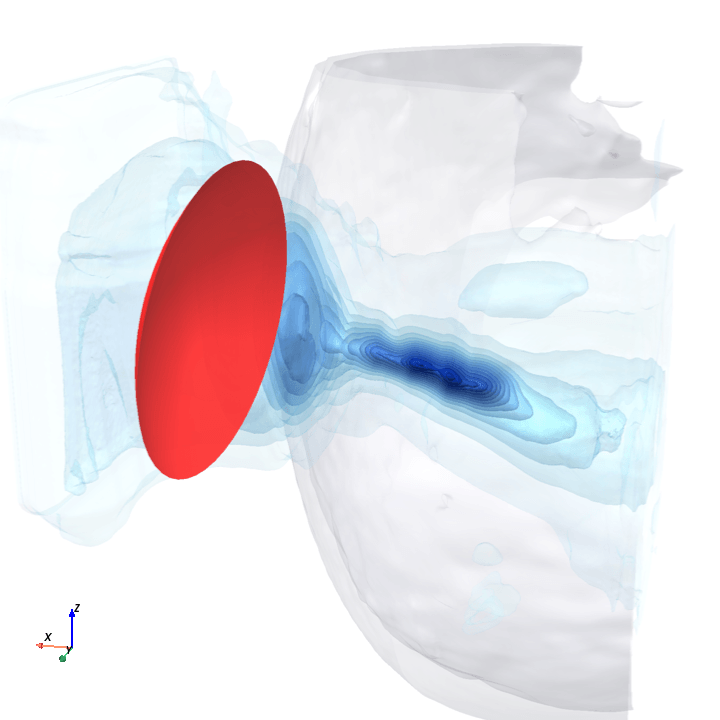
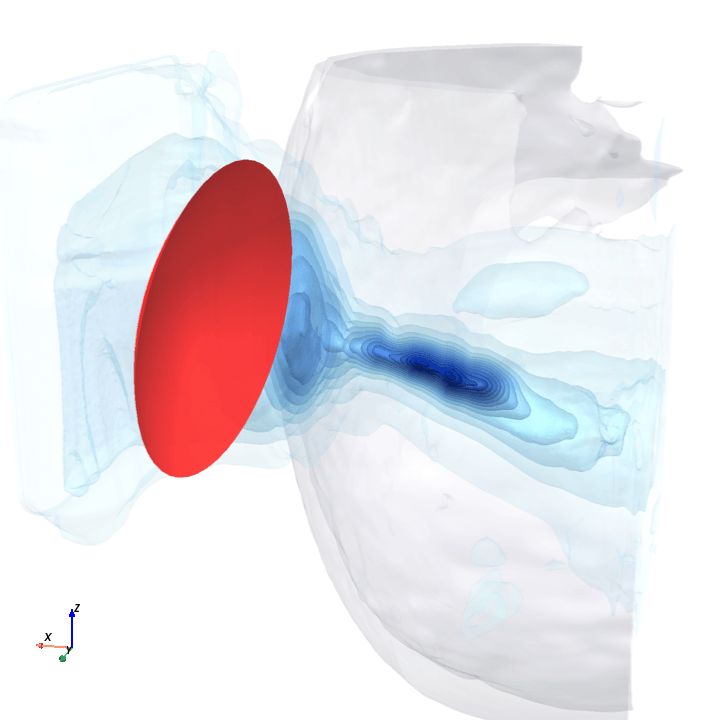
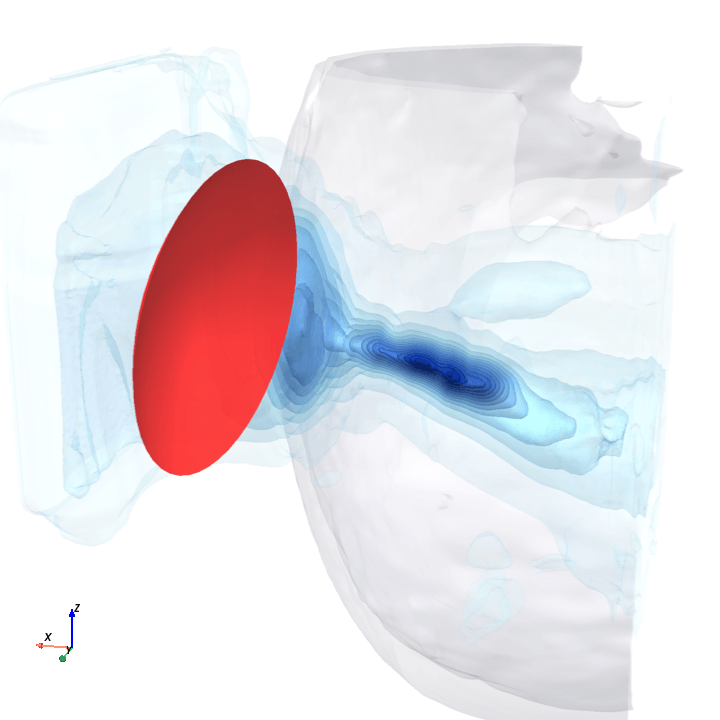
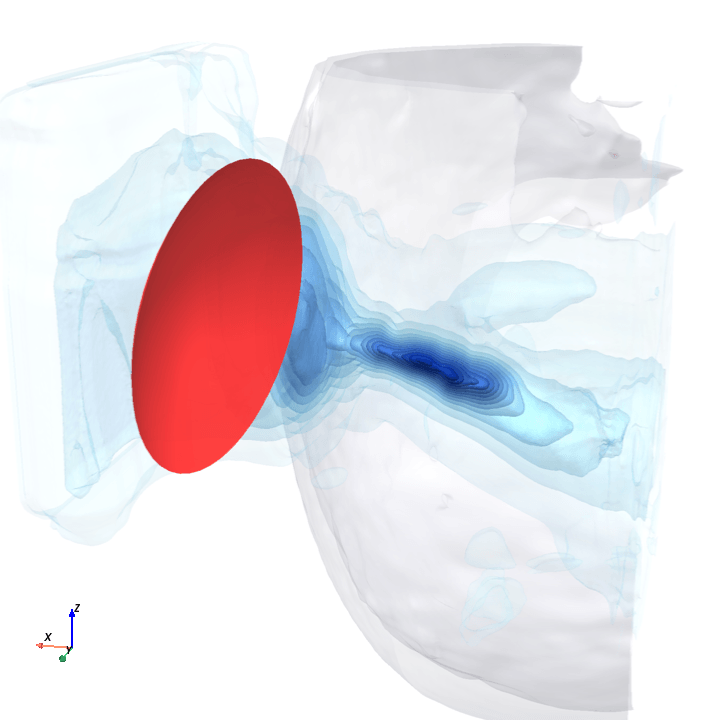
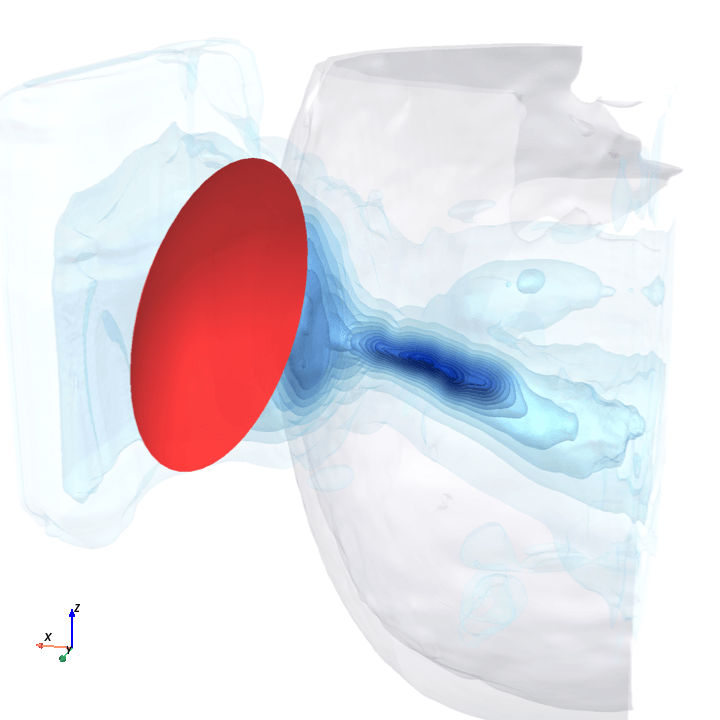
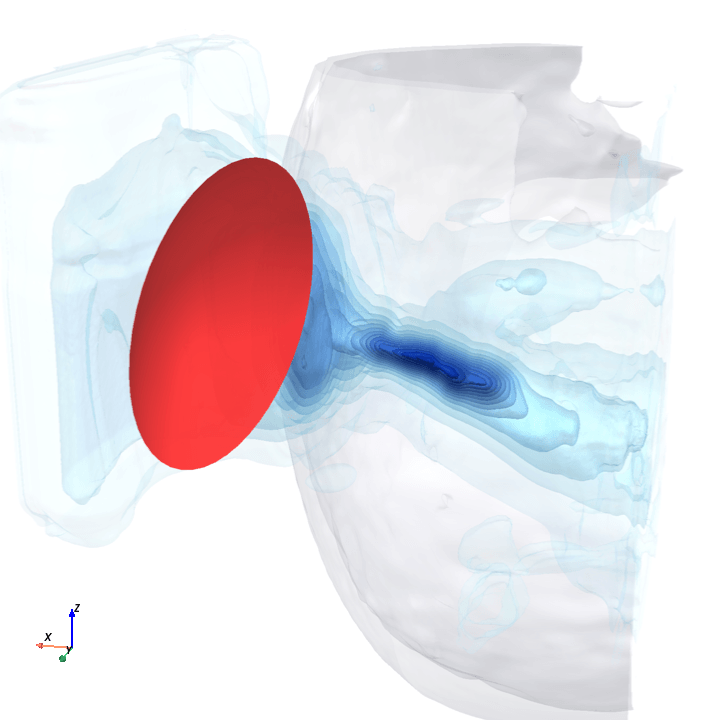
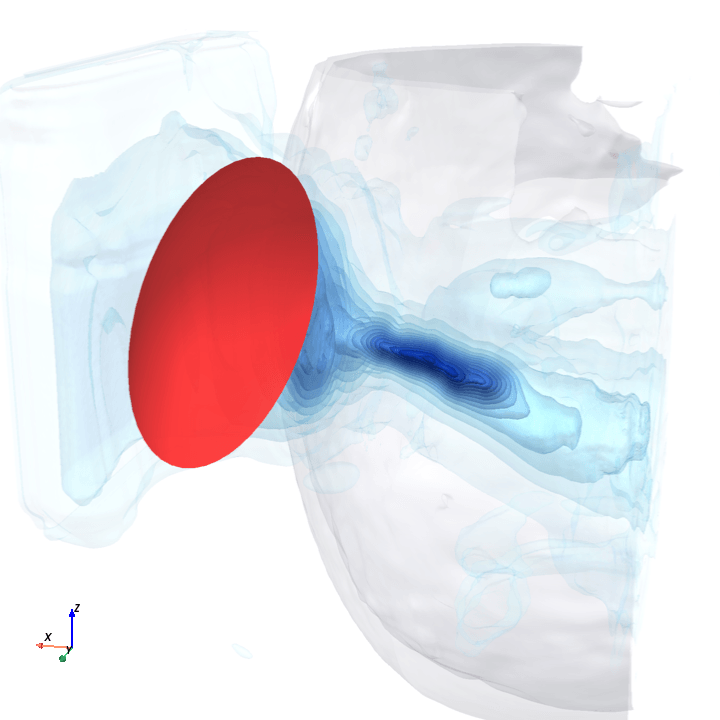
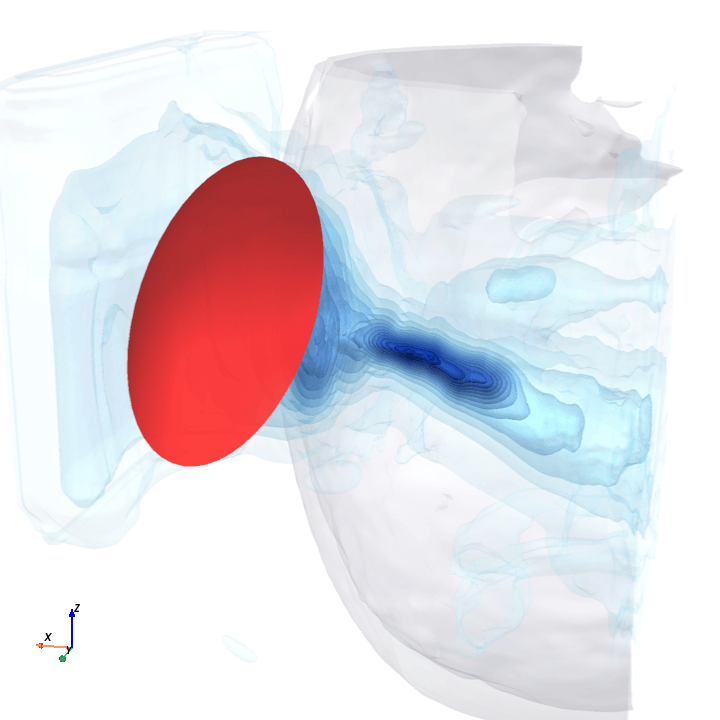
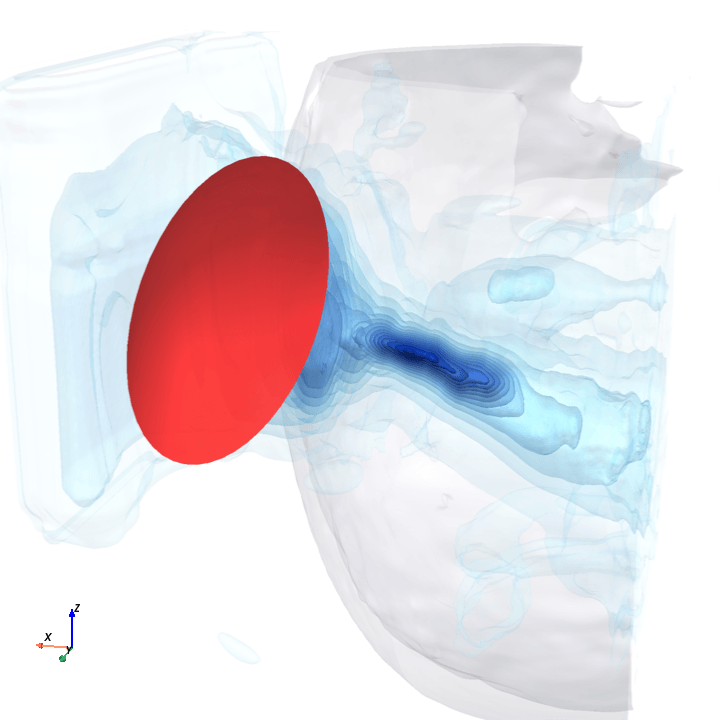
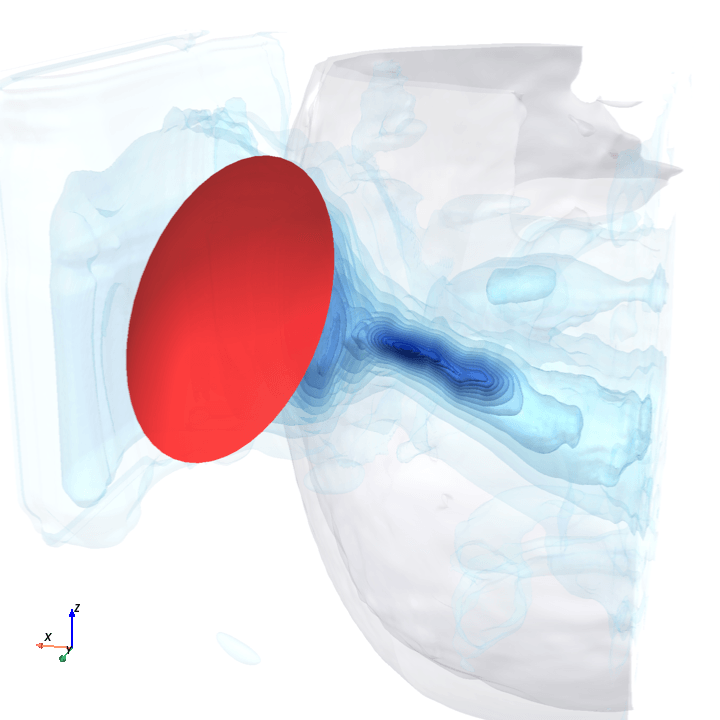
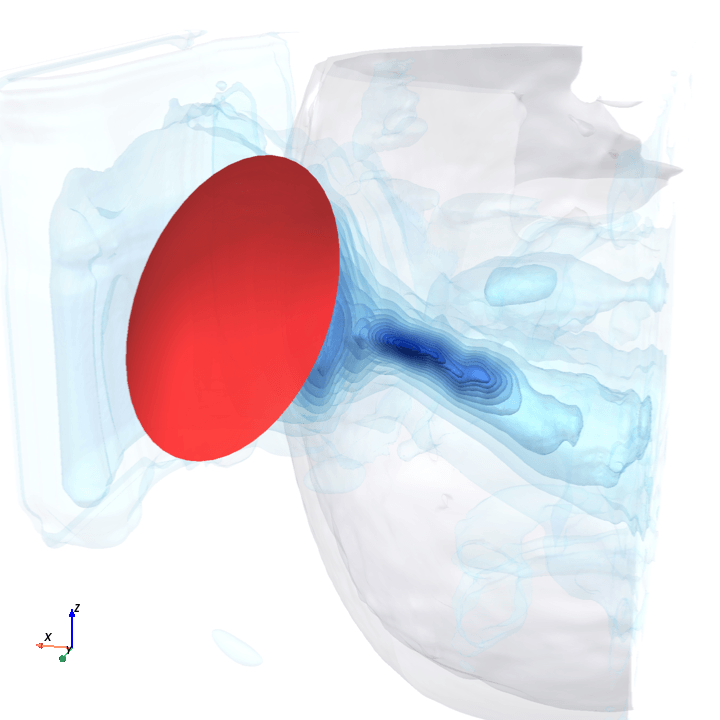
preparing 0/35 frames
8 of 128 bottleneck channels (mean-pooled over space) vs rotation angle
The channel curves are decently smooth across the sweep, without folds or abrupt jumps which is good! This seems to be weak qualitative evidence that gradient-based pose optimization should at least be feasible. Again, this is more of a sanity check that comes with what I hope to be a nice view into our model :)
Update (5.14.26)
The authors got back to me with the §3.2 details I’d flagged in note 1 , and confirmed I may share them here.
DeepTFUS is ~38M parameters; DeepTFUS-tiny is ~10M. My reproduction at base_width=16 is ~3.4M, about 1/3 the size of DeepTFUS-tiny and ~1/11 the size of the full model. Although I did not train a new model, this confirms my stated suspicion of my reproduction being capacity-bound (i.e., model too small).
Acknowledgments
Deep thanks to the DeepTFUS authors (Vinkle Srivastav, Juliette Puel, Jonathan Vappou, Elijah Van Houten, Paolo Cabras, and Nicolas Padoy) for releasing the ![]() TFUScapes dataset and for getting back to me with the architecture details. Full credit for the dataset and the architecture goes to them; this post is a reproduction attempt.
TFUScapes dataset and for getting back to me with the architecture details. Full credit for the dataset and the architecture goes to them; this post is a reproduction attempt.
Appendix
Full per-variant test metrics
The DeepTFUS paper reports three test-set metrics (the ones tabulated in sections 1 and 2). Throughout the project I also tracked the three metrics from the TUSNet evaluation suite (Naftchi-Ardebili et al., 2024 , the earlier deep-learning model for this same transcranial-ultrasound prediction task) that DeepTFUS is also susceptible to: focal_pressure_error (how close the predicted pressure at the ground-truth focal location matches the simulator’s), focal_iou_fwhm (how cleanly the predicted half-max region overlaps with ground truth’s), and inference_latency_s. TUSNet’s remaining metrics either don’t apply to DeepTFUS (phase aberration correction) or are restatements of the three paper-canonical ones (focal positioning, peak pressure).
These matter because clinical deployment of focused ultrasound depends on field properties beyond the peak’s location and amplitude. The fine-tuning section may discuss these effects qualitatively without putting the underlying numbers in the main flow.
| metric | stat | paper | base | A | B | C | D | E |
|---|---|---|---|---|---|---|---|---|
| relative_l2 | mean ± std | 0.414 ± 0.086 | 0.384 ± 0.078 | 0.389 | 0.388 ± 0.077 | 0.388 ± 0.077 | 0.422 ± 0.082 | 0.401 ± 0.081 |
| relative_l2 | median | 0.394 | 0.369 | 0.372 | 0.372 | 0.372 | 0.404 | n/a |
| focal_position_error_mm | mean ± std | 2.89 ± 2.14 | 6.49 ± 4.58 | 5.60 | 5.06 ± 3.57 | 5.11 ± 3.76 | 4.19 ± 2.93 | 5.32 ± 3.44 |
| focal_position_error_mm | median | 2.45 | 5.15 | 4.64 | 4.18 | 4.15 | 3.61 | 4.39 |
| max_pressure_error | mean ± std | 0.199 ± 0.158 | 0.225 ± 0.116 | 0.204 | 0.240 ± 0.106 | 0.239 ± 0.106 | 0.283 ± 0.105 | 0.129 ± 0.095 |
| max_pressure_error | median | 0.166 | 0.217 | 0.200 | 0.239 | 0.239 | 0.287 | 0.110 |
| focal_pressure_error | median | n/a | 0.528 | 0.487 | 0.502 | 0.496 | 0.475 | 0.421 |
| focal_iou_fwhm | median | n/a | 0.143 | 0.148 | 0.136 | 0.136 | 0.121 | 0.152 |
| inference_latency_s | median | 11.4 (RTX 4090) | 0.233 | 0.232 | 0.233 | 0.232 | 0.233 | 0.232 |
eval.py aggregates on the 597-sample test set. The first three rows are the paper-canonical metrics; the last three (focal_pressure_error, focal_iou_fwhm, inference_latency_s) are the TUSNet metrics that also apply to DeepTFUS. Lower is better on all rows except focal_iou_fwhm (higher is better) and inference_latency_s (informational). Bold cells are the project best per row. In the n/a cells, I had shut down my H100 before realizing I did not save the per-sample metrics for variant A (and one row for variant E).Notes
The paper does not specify:
- Total parameter count of the full DeepTFUS model (and its smaller “DeepTFUS-tiny” variant). I have no grounding for whether
base_widthshould be 16 or 64 or something else entirely. - U-Net depth and base channel width. Everything in §3.2 is described qualitatively (“four encoder stages”, “multi-scale features”) without numbers.
- The number
nof Fourier encoding frequencies used in the transducer positional encoding. The paper says “Fourier features” with no count. - Cross-attention head count and per-head dimension.
- Dynamic convolution kernel size and number of generated kernels per layer.
I emailed the authors asking for these and have not heard back at the time of writing. I went with what fit the 80GB of memory: base_width=16 (~3.4M params, at the small end of plausible for a 3D U-Net at this scale), depth 4, 8 Fourier frequencies, 4 cross-attention heads, dynamic-conv kernel size 3.
Update: the authors got back with the full spec; see the Update section.
The paper does not specify:
- Total parameter count of the full DeepTFUS model (and its smaller “DeepTFUS-tiny” variant). I have no grounding for whether
base_widthshould be 16 or 64 or something else entirely. - U-Net depth and base channel width. Everything in §3.2 is described qualitatively (“four encoder stages”, “multi-scale features”) without numbers.
- The number
nof Fourier encoding frequencies used in the transducer positional encoding. The paper says “Fourier features” with no count. - Cross-attention head count and per-head dimension.
- Dynamic convolution kernel size and number of generated kernels per layer.
I emailed the authors asking for these and have not heard back at the time of writing. I went with what fit the 80GB of memory: base_width=16 (~3.4M params, at the small end of plausible for a 3D U-Net at this scale), depth 4, 8 Fourier frequencies, 4 cross-attention heads, dynamic-conv kernel size 3.
Update: the authors got back with the full spec; see the Update section.
The two simplifications relative to the paper-text architecture, both for fitting on one 80GB GPU (batch size 4):
- One-way cross-attention instead of bidirectional. The paper specifies “two multi-head attention blocks”: one where the CT volume queries the transducer features, and one where the transducer queries the CT. The first direction is degenerate the way the paper encodes the transducer (as a single pooled token). The softmax over one key is identically 1, so that block collapses to a learned broadcast of a projection of the transducer vector, which is the same function the encoder’s DynamicConv layers already serve. Dropping it saves memory at no architectural cost.
- No FiLM in the decoder. The paper §3.2 puts FiLM modulation in the decoding path. I leave it off, partly to fit memory and partly because the paper’s own ablation table (Table 1, “No FiLM” row) shows lower
max_pressure_errorthan full DeepTFUS, with the other metrics within one standard deviation.
(There’s a third memory-driven choice: I apply cross-attention only at the bottleneck and the deeper encoder levels, not at the full 256³ input. Although the paper says “each encoder level” full-resolution CA blows past 80 GB no matter what else you do.)
The two simplifications relative to the paper-text architecture, both for fitting on one 80GB GPU (batch size 4):
- One-way cross-attention instead of bidirectional. The paper specifies “two multi-head attention blocks”: one where the CT volume queries the transducer features, and one where the transducer queries the CT. The first direction is degenerate the way the paper encodes the transducer (as a single pooled token). The softmax over one key is identically 1, so that block collapses to a learned broadcast of a projection of the transducer vector, which is the same function the encoder’s DynamicConv layers already serve. Dropping it saves memory at no architectural cost.
- No FiLM in the decoder. The paper §3.2 puts FiLM modulation in the decoding path. I leave it off, partly to fit memory and partly because the paper’s own ablation table (Table 1, “No FiLM” row) shows lower
max_pressure_errorthan full DeepTFUS, with the other metrics within one standard deviation.
(There’s a third memory-driven choice: I apply cross-attention only at the bottleneck and the deeper encoder levels, not at the full 256³ input. Although the paper says “each encoder level” full-resolution CA blows past 80 GB no matter what else you do.)
The exponent constant is , and the weights are normalized per-sample so :
This is paper Eq. 5. The subtraction is just numerical stability; it shifts the exponent into before exponentiation. Both pressures live in a per-sample log-normalized space, so the peak is around .
The exponent constant is , and the weights are normalized per-sample so :
This is paper Eq. 5. The subtraction is just numerical stability; it shifts the exponent into before exponentiation. Both pressures live in a per-sample log-normalized space, so the peak is around .
Concretely, with the un-log-transformed predicted pressure in :
It’s a temperature-controlled differentiable expectation of the voxel coordinate over a softmax of pressure. Smaller gives a sharper peak in the softmax, closer to true argmax; larger gives a softer support, biased toward the volume centroid. The hard argmax is but isn’t differentiable, so we can’t backprop through it.
Concretely, with the un-log-transformed predicted pressure in :
It’s a temperature-controlled differentiable expectation of the voxel coordinate over a softmax of pressure. Smaller gives a sharper peak in the softmax, closer to true argmax; larger gives a softer support, biased toward the volume centroid. The hard argmax is but isn’t differentiable, so we can’t backprop through it.